Amazon Textract
ToolJet can connect to Amazon Textract to extract text and data from scanned documents, forms, and tables. Textract can process documents of various formats, including PDF, JPEG/JPG, and PNG.
Before following this guide, it is recommended to check the following doc: Using Marketplace plugins.
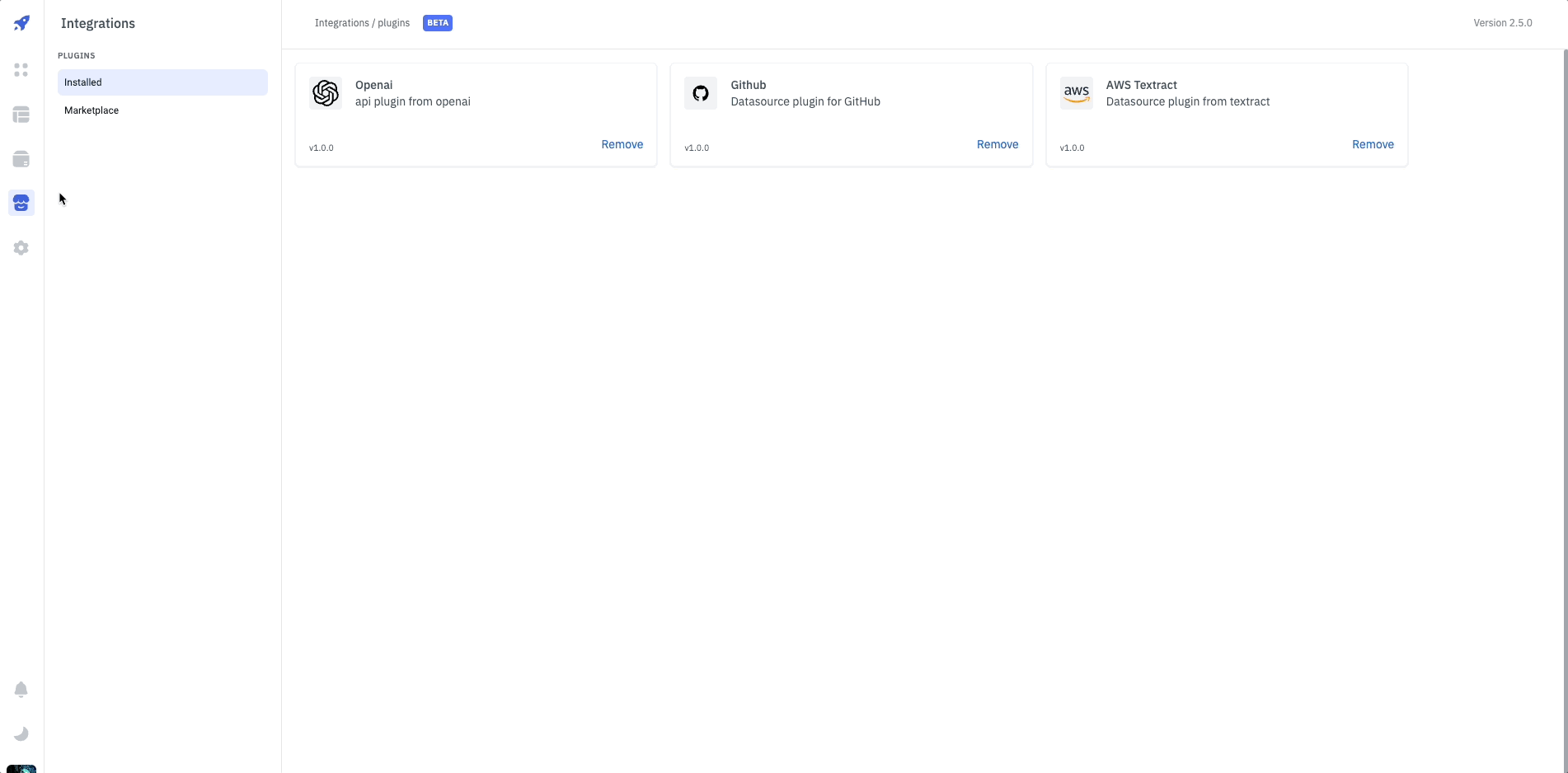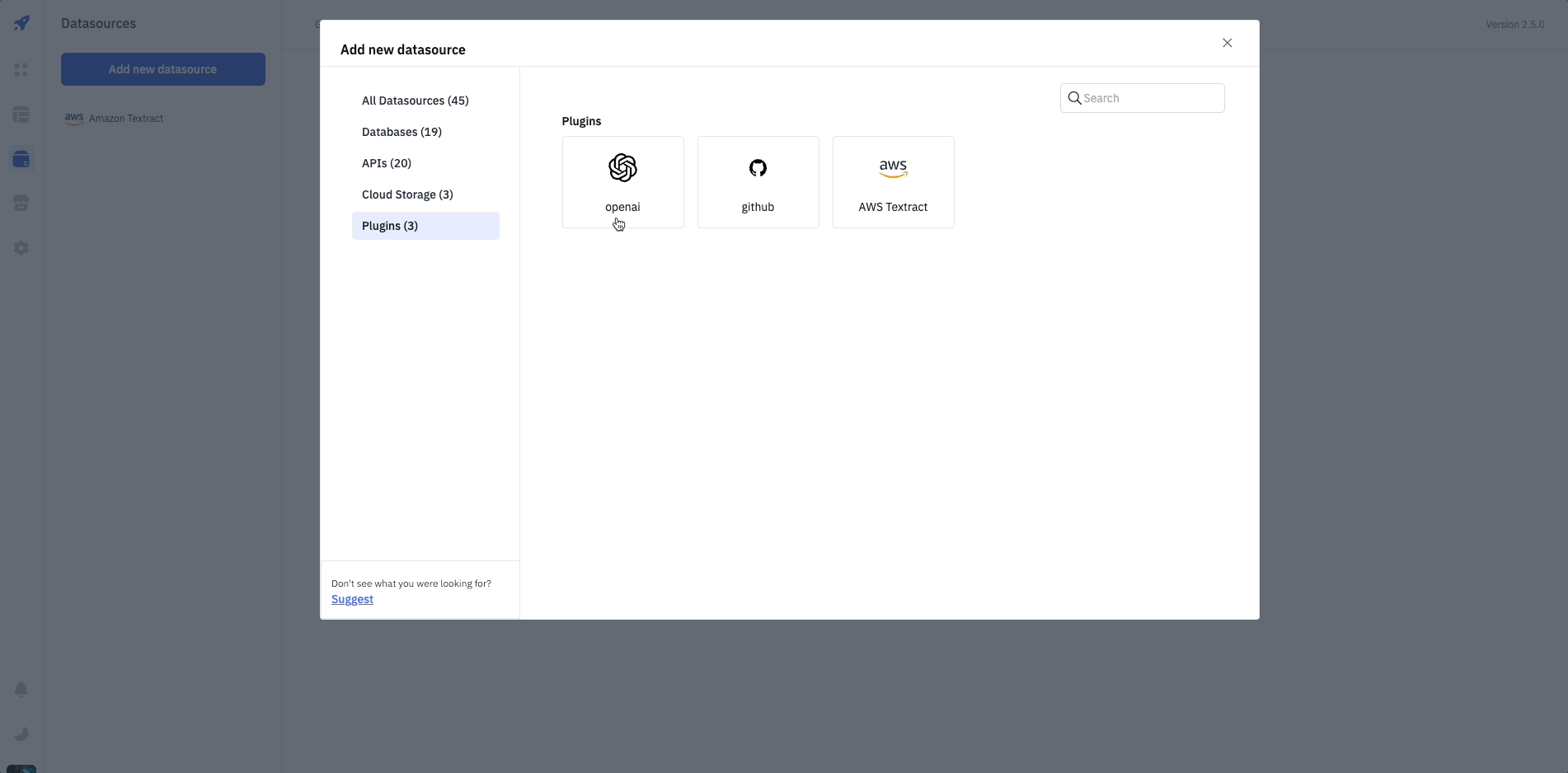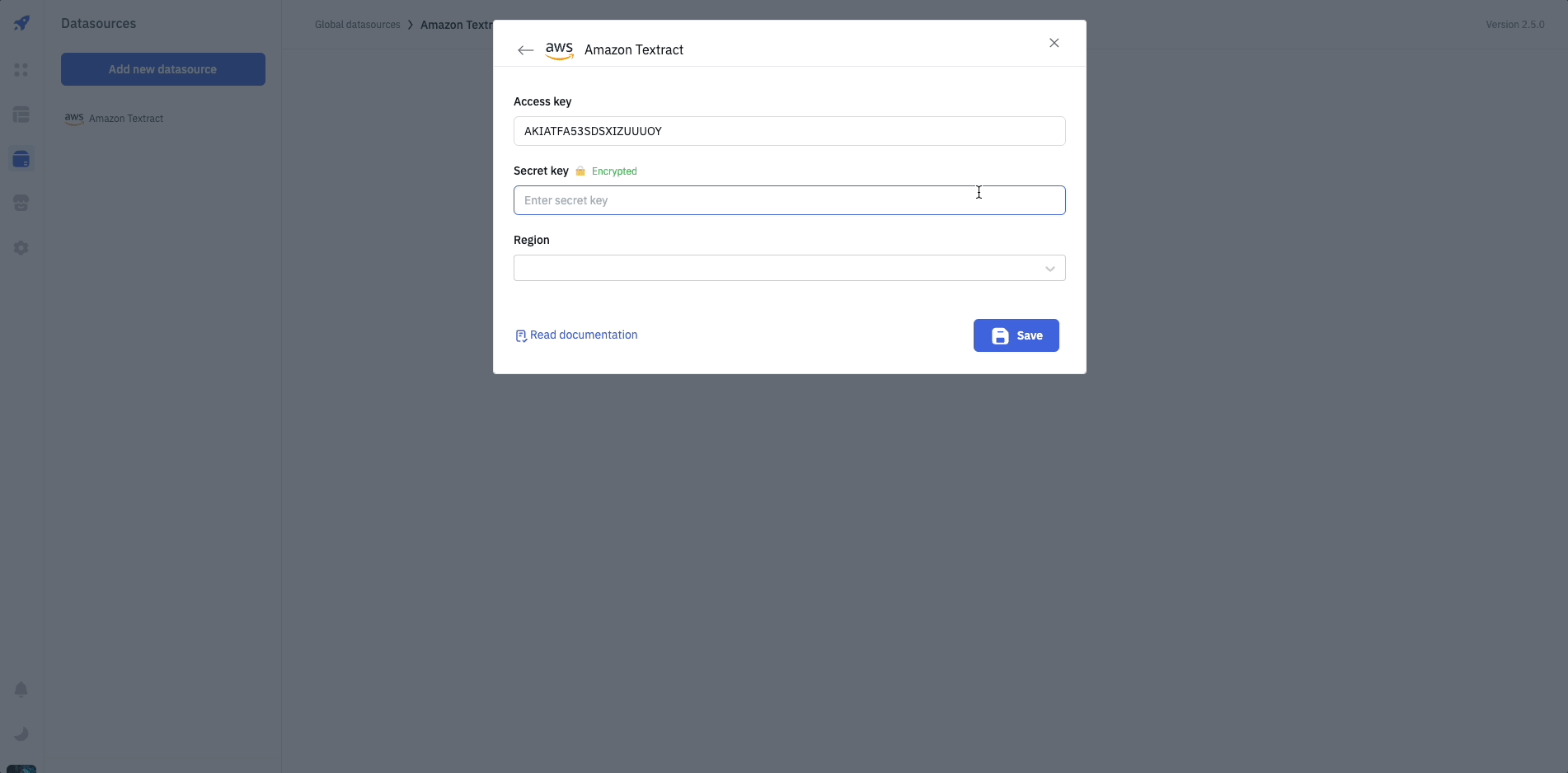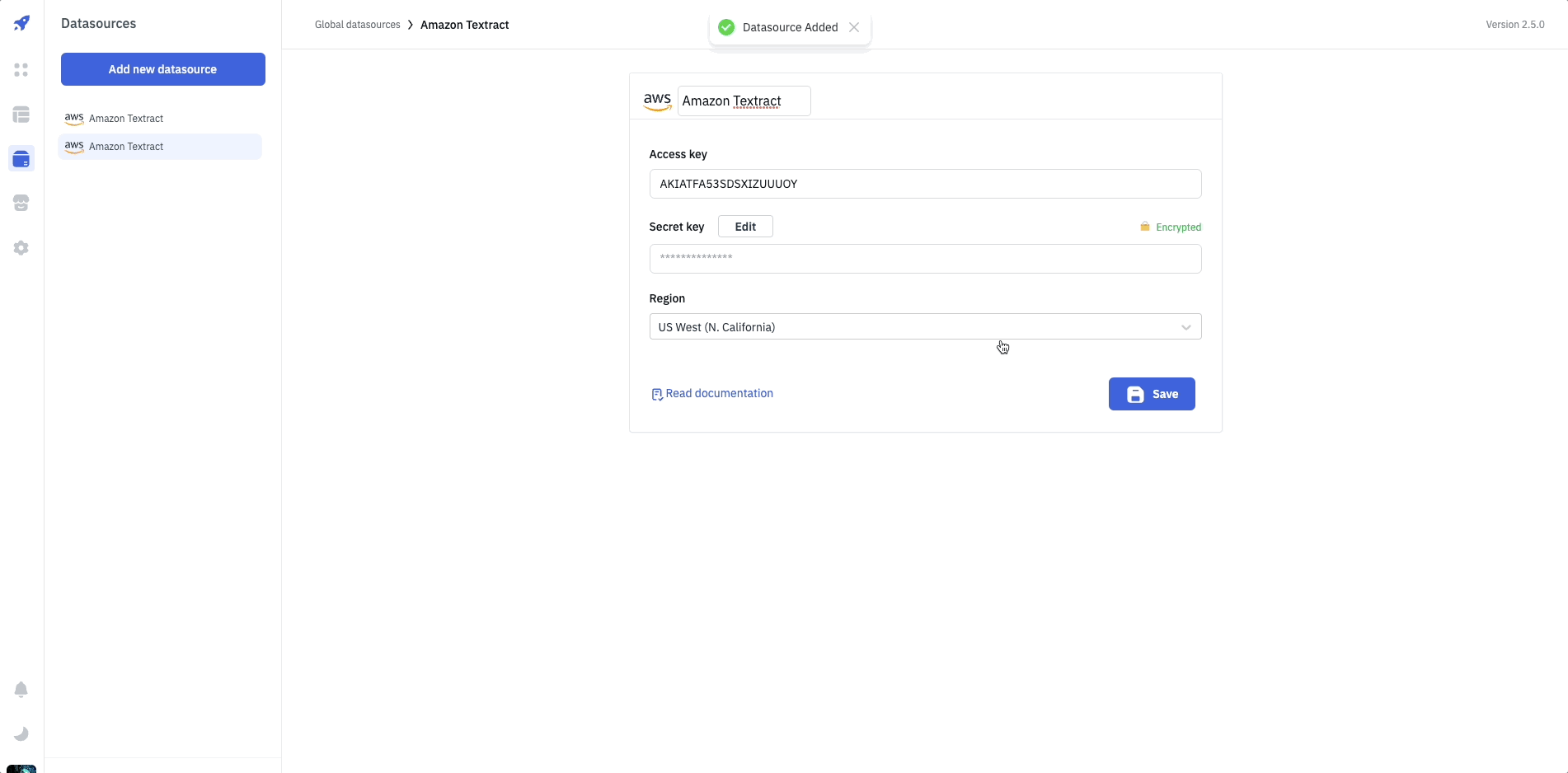
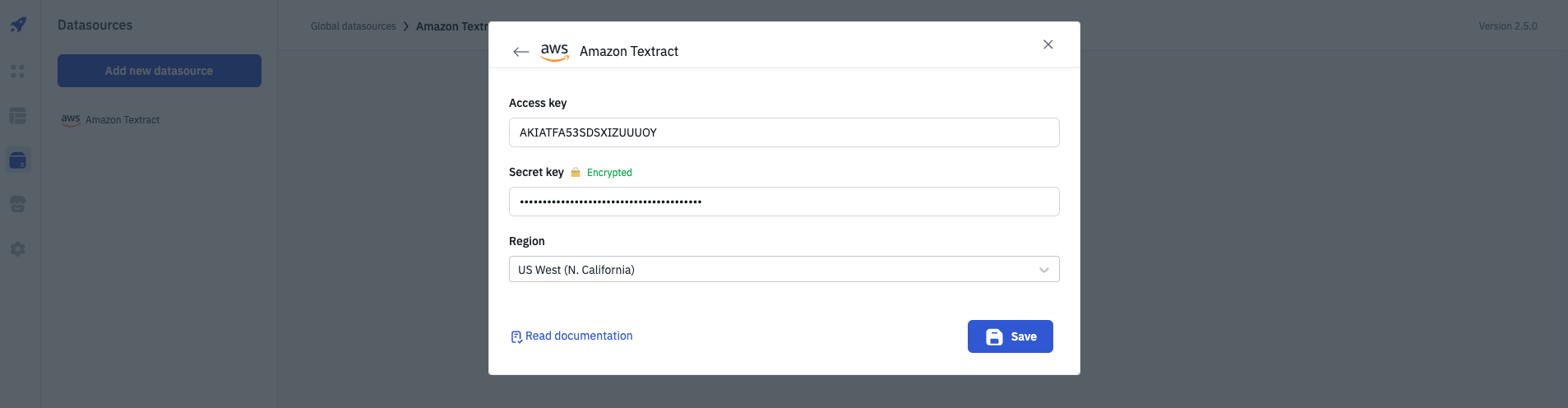
Connection
For connecting to Amazon Textract, following credentials are required:
- Access key
- Secret key
- Region
- Access to the S3 bucket is dependent on the permissions granted to the IAM role added for the connection.
- Only single page documents are supported. if there is a multipage PDF you can convert it to single page using available online tools.
Supported queries
The data returned by the queries is in JSON format and may include additional information such as confidence scores and the location of the extracted content within the original document.
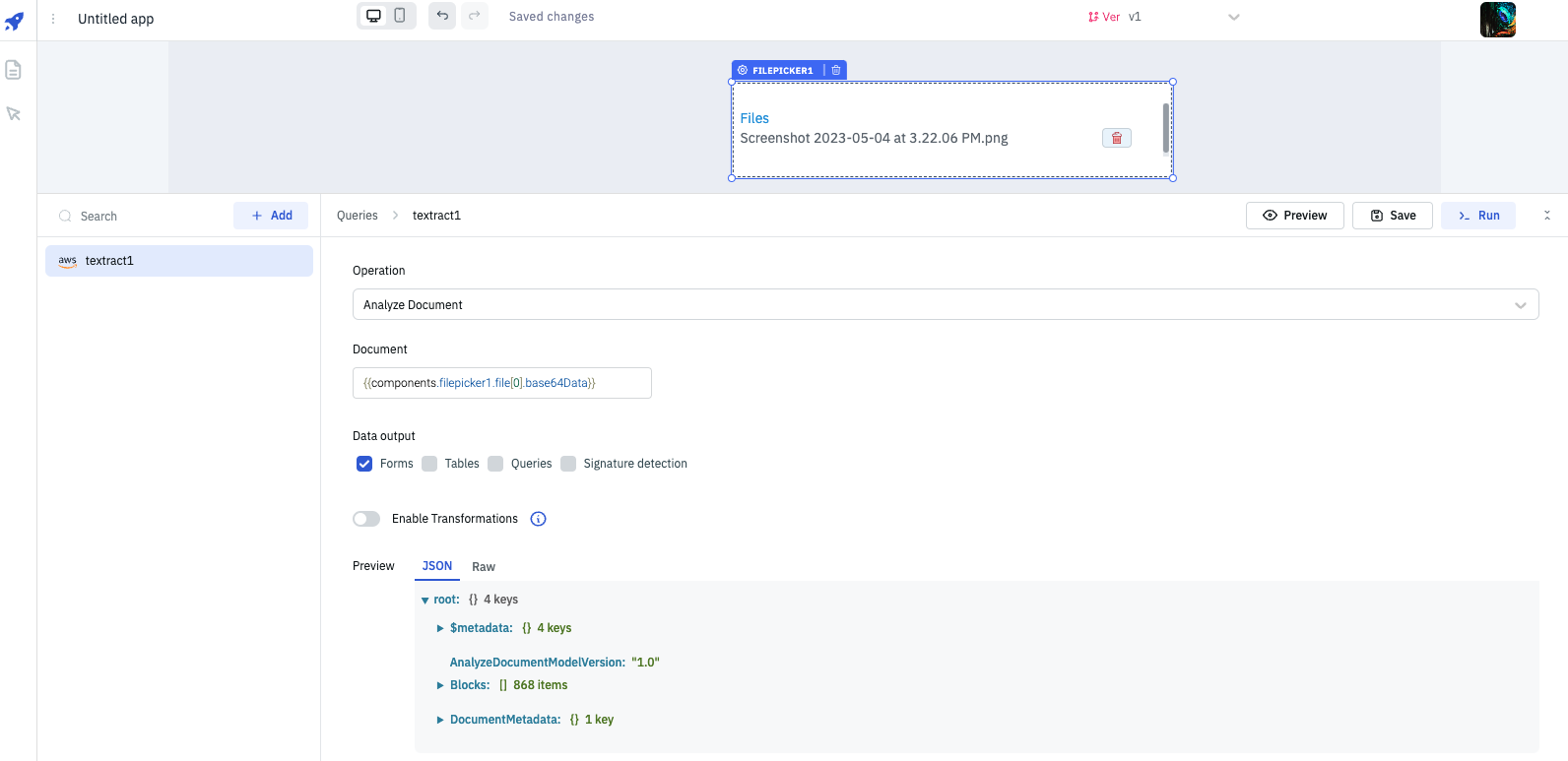
Analyze Document
This operation let's you to analyze the document by providing the document data in base64 format.
Required parameters:
- Document: Provide the document data in base64 scheme. Components like filepicker can be used to pick the document from local system and retrieve the base64 data dynamically using exposed variables. ex:
{{components.filepicker1.file[0].base64Data}} - Data Output: Select one or more type of data output of the document. The 4 types of data outputs are:
- Forms: Extracted data and text from forms, including field keys and values.
- Tables: Extracted table data, including column and row headers and cell contents.
- Queries: Extracted data from databases and other structured data sources.
- Signature Detection: Identification and extraction of signatures and signature blocks from documents.
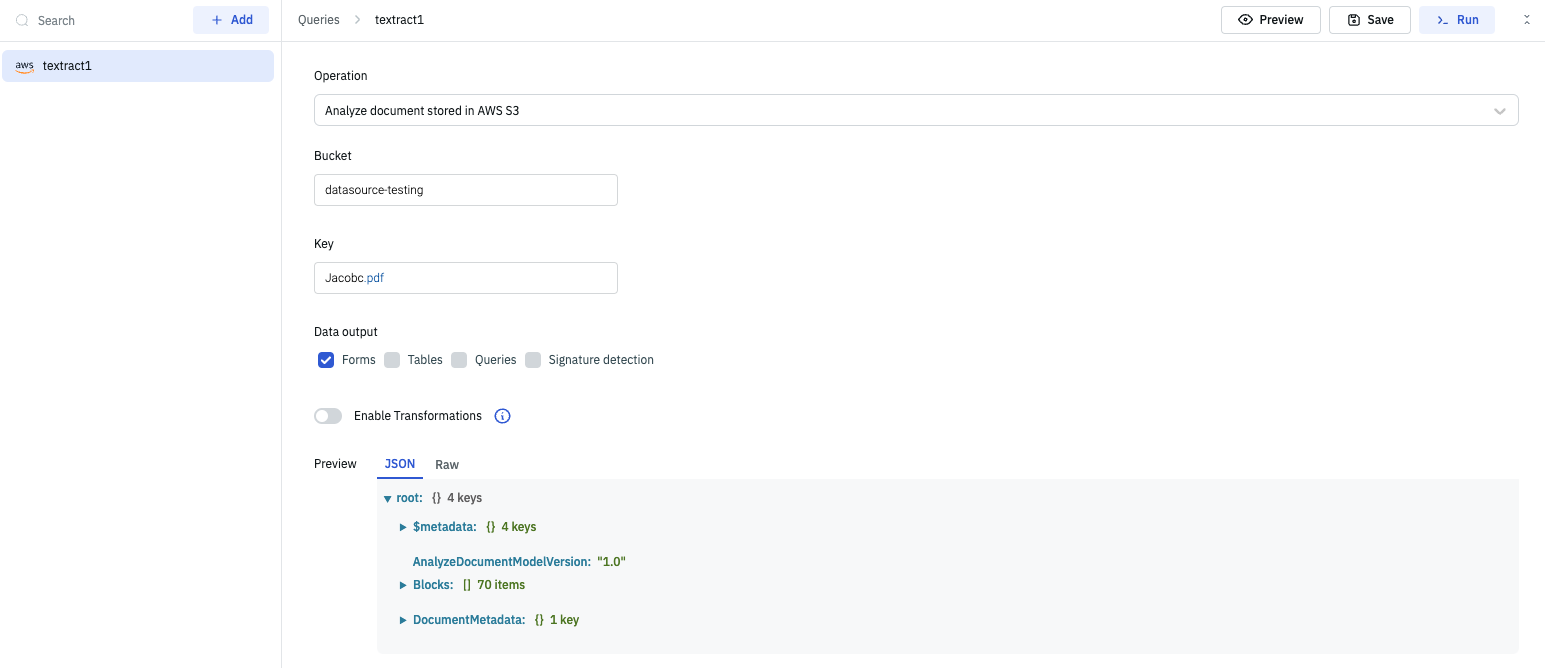
Analyze document stored in AWS S3
This operation let's you to analyze the document stored in your AWS S3 buckets by providing the bucket and object name.
Required parameters:
- Bucket: Name of the S3 bucket that has the document stored
- Key: Object name(document name) that needs to be extracted
- Data Output: Select one or more type of data output of the document. The 4 types of data outputs are:
- Forms: Extracted data and text from forms, including field keys and values.
- Tables: Extracted table data, including column and row headers and cell contents.
- Queries: Extracted data from databases and other structured data sources.
- Signature Detection: Identification and extraction of signatures and signature blocks from documents.